Offline Policy Evaluation: Run fewer, better A/B tests
How offline policy evaluation works, examples on how to use it, and lessons learned from building OPE at Facebook

TL;DR you’re probably wasting time, resources, and revenue running unnecessary A/B tests. Offline policy evaluation can predict how changes to your production systems will affect metrics and help you A/B test only the most promising changes.
A/B tests are essential for measuring the impact of a change or new feature. They provide the required information for making data-driven decisions. They also take a long time to run, are subject to false positives/negatives, and can give real users bad experiences.
Just like A/B tests became standard practice in the 2010s, offline policy evaluation (OPE) is going to become standard practice in the 2020s as part of every experimentation stack.
🤓 What is OPE?
At a certain point every company runs A/B tests. Simple changes, like changing text on a landing page, are easily tested with any A/B service available now. They can also test something more complex, like a decision making system. A decision making system could be a recommendation engine, a set of handcrafted fraud rules, or a push notification system. In machine learning jargon, decision making systems are called “policies”. A policy simply takes in some context (e.g. time of day) and outputs a decision (e.g. send a push notification). A perfectly data-driven company would measure the impact of any and every change to a policy.
At Facebook, I worked on the applied reinforcement learning team where our goal was to develop better policies for push notifications, feed ranking, and many other problems. Every time we created a new policy, or tweaked an existing policy, we would run an A/B test…and then wait several weeks to gather data to find out if this new policy was better than the current one.
What if we used historical data to evaluate policies offline? We could iterate much faster, and wouldn’t have to expose the not-as-good policy to any users. Then, we would only A/B test the policies that had a high likelihood of performing well, leading to fewer, better A/B tests. We used offline policy evaluation (OPE) methods to do this and wrote about it in our paper Horizon: Facebook’s Open Source Applied Reinforcement Learning Platform. OPE became a critical part of teams’ release cycles as a required step before A/B testing.
🧠 When should you use OPE?
Now you might be thinking OPE is only useful if you have Facebook-level quantities of data. Luckily that’s not true. If you have enough data to A/B test policies with statistical significance, you probably have more than enough data to evaluate them offline.
Imagine you work for a company that makes a mobile app and you want to test a change to your push notification policy. Currently the policy is very simple: if a user hasn’t used your app in 1 day, send them a push notification that says “Hello!” with 90% probability (10% chance you leave them alone). You’ve heard from users that this is annoying so you want to test changing the number of days, and the probability. A/B testing a bunch of different trigger days and probabilities will take a long time given the number of combinations. Ideally, you could use all the historical data you have from sending and not sending notifications to narrow down the policies and just A/B test the ones that are probably better.
OPE solves this problem by predicting how well a new policy will perform using only historical data.
Some domains need OPE more than others as the risk level of deploying a bad policy varies by problem space. While sending some annoying push notifications might not be too big of a deal, deploying a bad fraud policy or loan approval policy can lead to severely negative outcomes like financial loss or unfair bias.
From talking with a variety of companies, only a few have implemented rigorous OPE methods. Instead, most do some combination of the following:
- Ad-hoc analysis using historical data. This is definitely in the right direction. This is error prone though because the historical data does not accurately represent proportions of actions taken by the new policy. OPE methods explicitly correct for this distribution mismatch (see the inverse propensity scoring section below).
- Build a simulator: A truly accurate simulator would be better than any OPE method, but building an accurate simulator is significantly harder than finding a good policy.
- Use supervised learning evaluation metrics. These metrics coexist with OPE. Often times supervised learning models are a small piece of a policy. Just as you’d evaluate a supervised learning model with metrics like F1 score, precision, and recall, you’d evaluate a policy with OPE metrics.
- Run a sh** load of A/B tests: This is where most companies end up. A/B tests are time consuming, can give users bad experiences, have a higher likelihood of false positives the more you run, and can lose companies a lot of money. OPE is not meant to replace A/B testing, but rather serve as a filter on what changes make it into an A/B test.
📈 Real use cases for OPE
Let’s go over some real problems that could benefit from OPE.
Growth marketing: Deciding when and who to send an email, push notification, or SMS (please no 🙏) boils down to a policy optimization problem. Policies are iterated on to find the right balance between getting users to pay attention to your service and not annoying them. Section 9 in Horizon: Facebook’s Open Source Applied Reinforcement Learning Platform details how we used reinforcement learning and OPE to significantly improve the push notification system at Facebook. OPE saved us months of time A/B testing as we were able to pick only the most promising policies to A/B test.
Example rules-based push notification policy:
Example machine learning powered push notification policy:
Fraud policies: Blocking fraudulent transactions is important for any online business that takes payment from customers. Fraud policies come in many forms and usually use some combination of hand written rules and machine learning to figure out which transactions to block. Tweaks to any of the ML models, logic, or parameters in a fraud policy could result in serious monetary loss that could be prevented by OPE.

Ranking systems: Recommender / ranking systems like Facebook’s newsfeed, Airbnb’s search ranking, the Netflix home screen, etc. use user and content features to decide how to rank the top N pieces of content for each request. These systems are usually composed of signals from ML models (P(click), P(like), …), weights on these signals, and logic to combine them. There are many degrees of freedom within these policies leading to way too many combinations to A/B test.
Credit models: From deciding if someone should get a loan and at what interest rate to determining someone’s margin limit on a trading platform like Robinhood, credit policies are important parts of many consumer-facing financial companies. It’s important to understand the risk and fairness of policies before they are rolled out to real users.
Robotics: I don’t have too much to say about this area besides I hope autonomous car companies are doing some form of OPE 😬.
🔎 OPE methods & examples
Let’s dive into the three most fundamental OPE methods — inverse propensity scoring, the direct method, and the doubly robust method. Nearly all new papers in the OPE space build off of these 3 methods. For each approach I’ll go over how it works and show how it can be used to evaluate a simple push notification policy like the one described above.
Python implementations of these methods can be found in the offline-policy-evaluation repo.
To get started, let’s put together a sample push notification policy that would run every day across all users, and generate a few sample logs from it. We’ll then use OPE methods to evaluate potential new push notification policies. When describing a policy, we want to know what the probability of taking each action is given a specific context.
Sample push notification policy
This push notification policy is pretty simple. If a user hasn’t opened our app in more than a day, send them a push notification with a 90% chance. If the user has been active within a day then don’t send anything with a 90% chance. In both cases there is a 10% chance to take the opposite action. This is an example of adding exploration to a policy using an epsilon-greedy exploration strategy. Exploration is required to conduct OPE because there needs to be data from every action, even if it’s a small amount. 10% is a high number for exploration; real systems typically use <1%.
Under our push notification policy above, let’s generate some logs:
Reward in the logs is computed as follows. If a user opens their app on a given day, this gets a reward of 10. If the user was sent a push notification on that day, subtract 3 from the reward, because we should penalize bothering a user with a notification. For example, a reward of 7 means that a user was sent a notification and opened the app that day (10–3).
The logs above (intentionally) show a clear relationship. If a user has been recently active, it’s a good indication that they don’t need a notification to open their app today. Instead, if a user hasn’t been active in a while, sending a notification makes sense to get them to open their app again.
Now let’s get into some of the math! Sorry for yelling, but it’s going to be fun.
Inverse propensity scoring (IPS)
IPS evaluates a new policy by correcting the action distribution mismatch between the new policy and the policy that generated the data (logging policy) [1]. To put it another way, if your existing logging policy had a high chance of doing something good, but your new policy has a small chance of taking that same action, the new policy would be penalized. Conversely, if your existing logging policy had a high chance of taking a bad action and your new policy has a lower chance, this is good for the new policy. Reward for more good, penalize for more bad.
Formally, the IPS estimate is defined as follows:
Where,
Vips= the expected average reward per decision under the new policyn= the number of samples in your historical datav(ak|xk)= the probability that your new policy takes the logged action given the logged contextu(ak|xk)= the probability that your logging policy takes the logged action given the logged contextrk= the logged reward from taking that action given that context
Now let’s design two new policies — one better than our logging policy and one worse than our logging policy. Our manager won’t take our word for it, so let’s prove it using OPE.
The “good” policy we want to test:
This new “good” policy is designed to bother active users less. Now, instead of aggressively sending notifications a day after a user has gone inactive, we will wait 5 days. This policy should perform better because we saw in the data that active users don’t really need to be reminded to open the app.
New “bad” policy we want to test:
This new “bad” policy is the opposite of the “good” policy (we flipped the >to a <). Now, active users will get spammed with notifications and inactive users will be left alone. Far from the perfect growth strategy 😬, but we all make mistakes.
Now let’s score both of the new policies using IPS:
IPS correctly identifies that the new “good” policy is much better than the logging policy and the new “bad” policy is much worse. The output values represent the expected reward you would get for each decision you make under the respective policy. In case it isn’t obvious… don’t A/B test the new “bad” policy 🙃.
Direct Method (DM)
The DM takes a different approach to OPE. It builds a predictive model of reward given context and action using historical data, rather than trying to correct for the mismatched action distribution like IPS. Using this reward model to predict the reward, the new policy can be evaluated across all the historical contexts and the expected reward for each logged example can be computed under the new policy.
Formally, the DM estimate is defined as follows:
Where,
Vdm= the expected average reward per decision under the new policyn= the number of samples in your historical datav(a|xk)= the probability that your new policy takes an action given the logged contextr(xk|a)= the predicted reward given a context and action
Just as we did with IPS, let’s use the offline-policy-evaluation library to score our “good” and “bad” policy with the direct method. For the direct method’s reward model we are using a gradient boosted decision tree (GBDT).
OPE scores using the direct method:
While the values differ from IPS, the story is the same. The direct method predicts that the “good” policy is indeed better and the “bad” policy is indeed worse. Using multiple OPE methods can give us more confidence as we decide which policies to test on real users.
Doubly Robust Method (DR)
The last method I’ll go over is the doubly robust method [1]. This method is interesting in that it combines IPS and the DM in a clever and beneficial way. As said in the DR paper,
Doubly robust estimators take advantage of both the estimate of the expected reward
rand the estimate of action probabilitiesuk(a|x)… If either one of the two estimators (i.e., DM or IPS) is correct, then the estimation is unbiased. This method thus increases the chances of drawing reliable inference. [1]
As demonstrated in the paper, this method is a strict improvement over both the direct method and IPS.
Formally, the DR estimate is defined as follows:
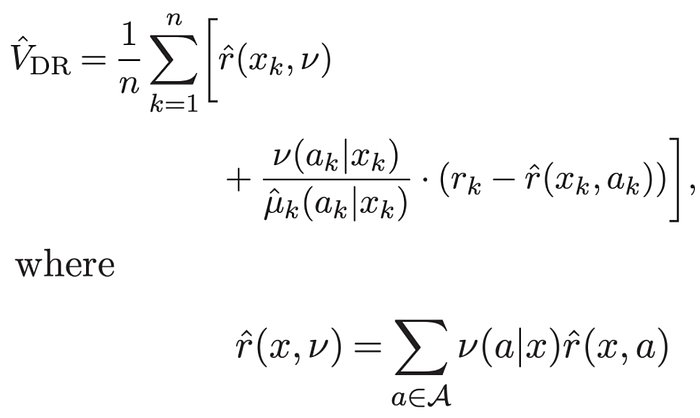
Where,
Vdr= the expected average reward per decision under the new policyn= the number of samples in your historical datav(ak|xk)= the probability that your new policy takes the logged action given the logged contextuk(ak|xk)= the probability that your logging policy takes the logged action given the logged contextrk= the logged reward from taking that action given that contextr(xk|ak)= the predicted reward given a context and action
In the formula above you can see that the doubly robust method takes the direct method and applies a correction based on the action distribution mismatch and reward model prediction error. If the reward model prediction error is 0 on a specific sample, then the entire second term cancels out and you are simply left with the direct method. As the doubly robust paper puts it, “…the doubly robust estimator uses [the reward model] as a baseline and if there is data available, a correction is applied” [1].
Let’s now try out the doubly robust method on our push notification policies:
Again, while the absolute scores differ between methods, the conclusions are the same. Go A/B test the “good” policy and toss the “bad” policy.
😅 OPE on real world problems can get hard fast
As with any good data science problem, OPE can get much more challenging to do well as you apply it to more complicated problems. Real-world problems may have some — or god help us, all — of the elements below:
- Huge action spaces: Many recommender systems have tons of content that could be recommended at any given time, meaning the action space could be really large (not just “send” or “don’t send”). In these cases actions are typically described by a set of features, just as the context is. Figuring out how to score actions, which actions to score, and how many actions to score in this case is another “fun” research problem.
- Slate ranking: Often in the case of ranking problems you don’t just pick the single best piece of content. Usually, you are picking a “slate” of items (e.g. the top “N”). Facebook newsfeed, Netflix, Reddit, and YouTube all work like this. The OPE methods above work well when you are trying to evaluate the effect of picking 1 action, but what happens when you need to pick the best slate of “N” actions? Luckily, enough crazy researchers work on this stuff and Langford et al come to the rescue with Off-policy evaluation for slate recommendation 🙏.
- Sequential problems: Above we focused on non-sequential decision making problems, typically solved with contextual bandits or rules-based systems. That is, we ignored optimizing over a “sequence” of decisions as you would do in a reinforcement learning setup. OPE methods must be adjusted when policies are optimizing over a sequence of actions.
👋 The end
Thanks for reading and if you ever want to talk about offline policy evaluation or have questions email me at edo@banditml.com or comment below.
Sources
[1] Doubly Robust Policy Evaluation and Optimization — https://arxiv.org/abs/1503.02834
[2]Horizon: Facebook’s Open Source Applied Reinforcement Learning Platform — https://arxiv.org/pdf/1811.00260.pdf
[3] Offline policy evaluation — https://github.com/banditml/offline-policy-evaluation
